|
|

论文地址:
图相关知识:
仅简要的叙述一下图的相关概念。图由顶点和边组成,分为有向图和无向图,有向图G的边是有方向的,边表示由一个结点A指向另一个结点B,表示A到B路径是通的,B到A不通(如下图a)。无向图G的边是无方向的,表示A到B路径可通,B到A路径可通(如下图b)。
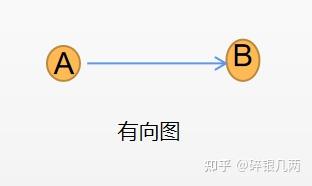
a
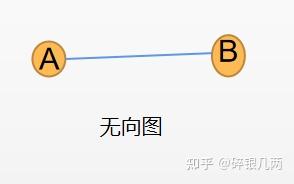
b
一、 概述
在图像处理方面,之前的方法都是先将图预处理成能被神经网络处理的格式,例如将图表示成结点序列,但这种方法会丢失很多拓扑信息;而GNN可以直接处理图,将图或者图中的结点映射为向量,在图像处理上具有更大的优势,能更好地利用图的拓扑信息。文章首次定义了图神经网络的理论基础,GNN的核心思想是:利用节点与节点之间的连边关系,基于共享参数和信息传播的理念,学习出节点的表达向量,也就是用路径可达的周边结点去学习目标节点的表示。
图神经领域的应用可以分为专注于图的应用(Graph-focused)和专注于结点的应用(Node-focused)。
- Graph-focused:函数T专注于图本身与结点n无关,在图的结构数据集中完成分类器和回归器。如下图a中为化学分子结构,需要预测分子结构是否对人体有害,则使用Graph-focused的方法判断分子结构是否有害,而不是判断每个原子的有害性。
- Node-focused:专注于结点,如下图b中是一个城堡图片,判断图中每一个结点是否属于城堡内部,此时需要每一个结点的特征,并预测结点的类别。
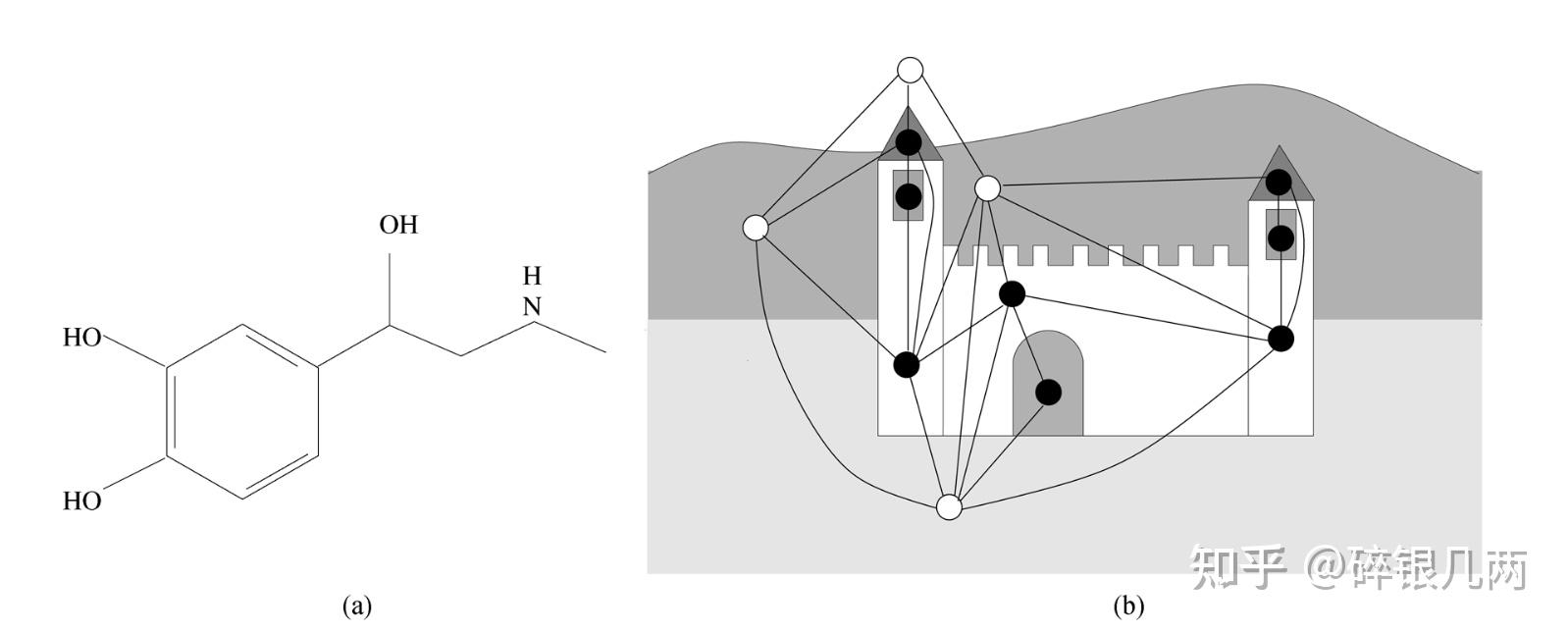
Graph-focused(左) & Node-focused ( 右 )
二、Method
假设存在一个图-节点对的集合D = GxN, G表示图的集合,N 表示节点集合。图领域可以表示成一个有如下数据集的监督学习框架。
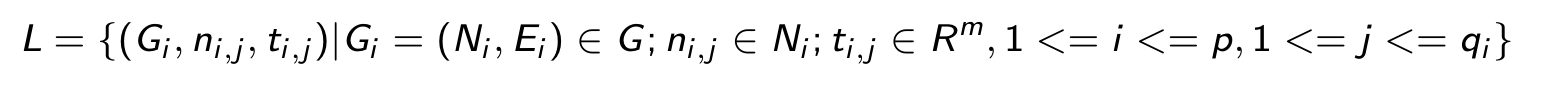
其中, n_{i,j} ∈ N_i 表示集合 N_i ∈ N中的第 j 个节点, t_{i,j} 表示n_{i,j} 的标签。
不理解?没关系,继续往下看。
GNN可以用于positional graph 和nonpositional graph。
- nonpositional graph是指结点的邻居节地没有顺序关系,可以随意排列。
- positional graph是指对于一个结点,需要为其所有邻居指定一个独一无二的整数位置。位置用injective function 计算, 如下:
v_n : ne[n] → 1, ...|N|
GNN算法是怎样的?


GNN算法主要分为两个步骤:forward 和backward。GNN的forward主要包含两部分:传播和输出;而backward用于更新梯度,训练网络。
此处仅介绍GNN的forward,GNN的理论基础是Banach的不动点理论。对于给定图G,其每个结点都有自己的特征,连接结点之间的边都有其特征。本文中结点n的状态用 x_n ∈ R_s 表示,该节点的输出用 o_n 表示,GNN的学习目标是获得每个结点感知图的状态,此处可以认为结点的状态包含了来自其邻接点的信息。进行forward时需涉及两个函数,分别为局部转移函数和局部输出函数。
f_w 为local transition function:局部转移函数主要是将邻居结点的边的信息结合在一起得到当前结点的状态向量,且其对所有结点都是成立的,因此其是一个全局共享的函数,也是一种减少模型参数量的做法。
g_w 为local output function:局部输出函数是将结点的特征和状态向量转为输出向量。那么x_n 和o_n的更新方式如
下:
x_n = f_w(l_n, l_{co[n]}, x_{ne[n]}, l_{ne[n]})
o_n = g_w(x_n,l_n)
其中 l_n 表示n结点的特征, l_{co[n]} 表示边的特征, x_{ne[n]} 邻居结点的状态, l_{ne[n]} 邻居结点的特征。
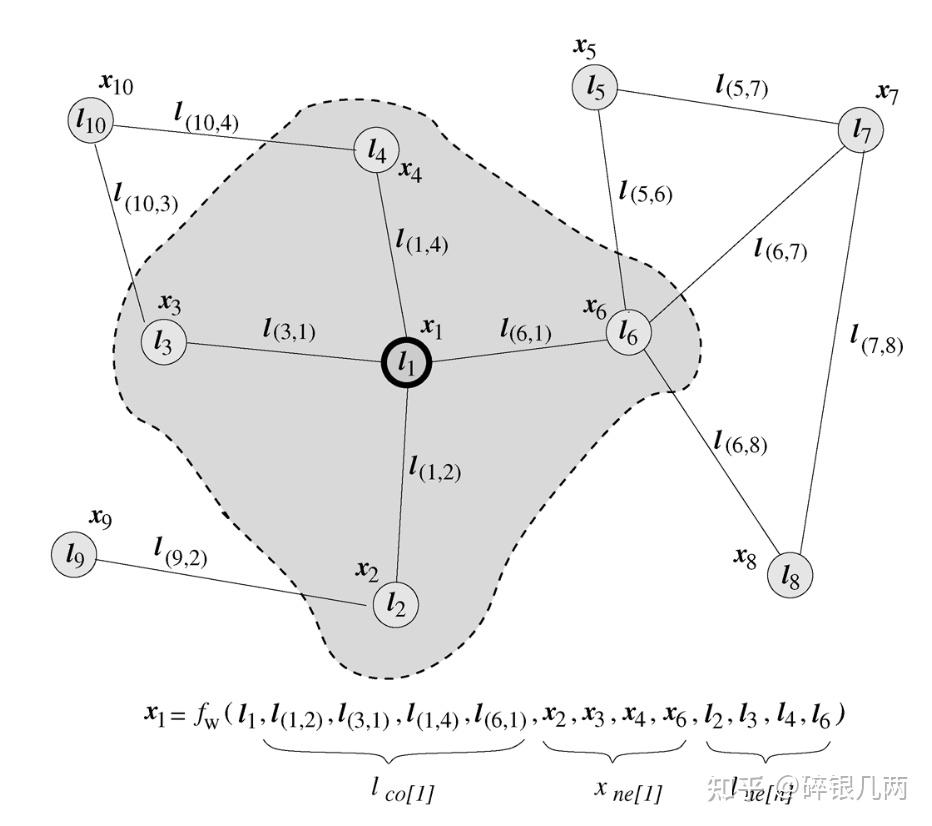
结合上图和上方公式,计算 x_1 需利用与当前结点 1路径可达的邻接点2, 3,4, 6的状态,邻接点特征以及通向此结点的边的状态来计算,此为一次传播过程,此时可以认为结点1包含了其邻接点的信息,而 g_w 是来描述如何用于下游任务。计算过程如下图所示:
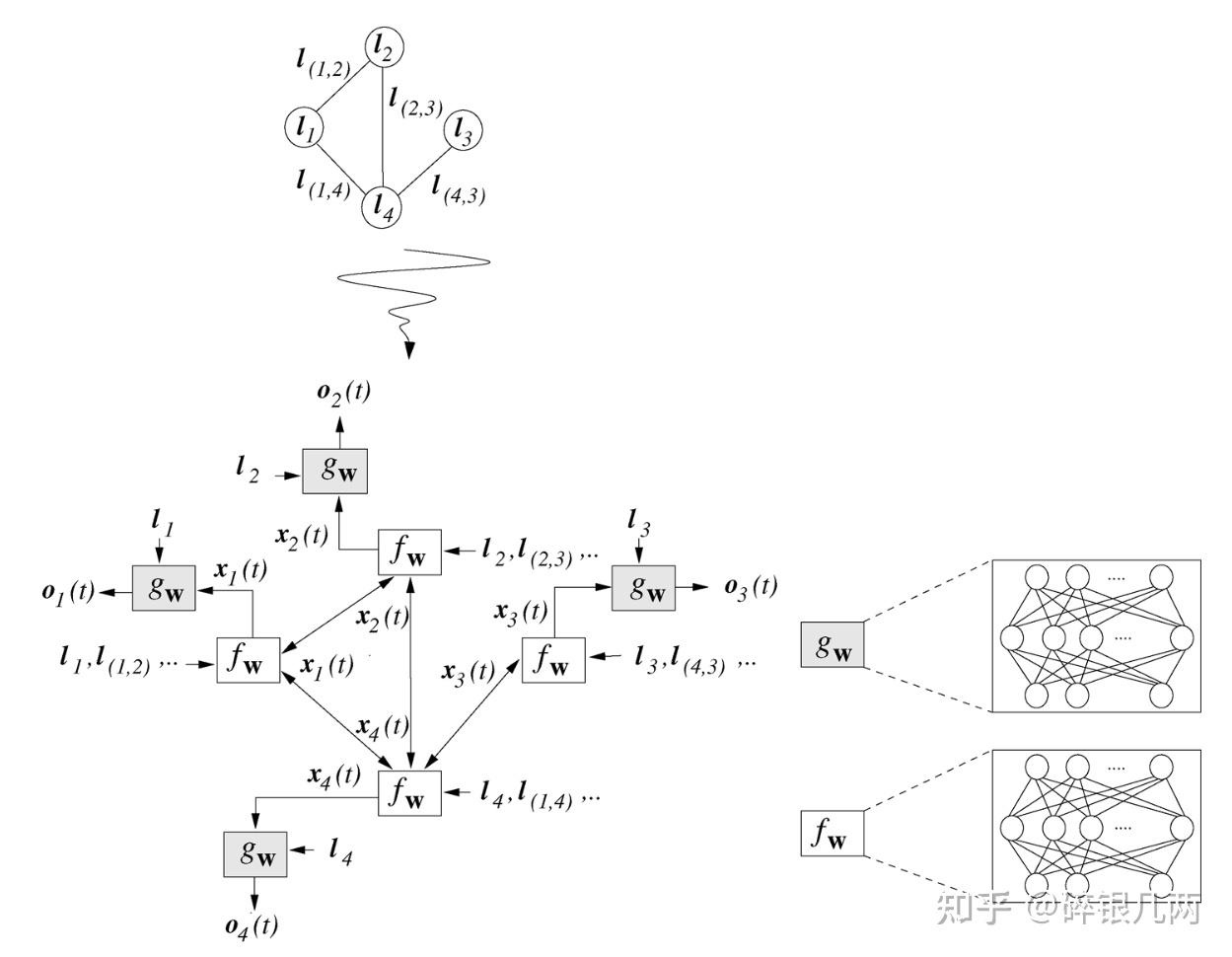
计算过程
前面有提到图神经网络适用于positional graph 和nonpositional graph, 上述公式里的 x_n 和 o_n 是对positional graph而言, 那么对于nonpositional graph,计算x_n则略有不同,是简单的加权和,因为对于nonpositional graph ,其结点之间无顺序。公式如下:
x_n = \sum_{u \in {ne[n]}} h_w( l_n, l_{(n,u)}, x_u, l_u)
如何让每个结点都感知图上所有结点的状态呢?
上面简述了GNN 的一次传播过程,经过一次传播之后,我们可以认为结点1已经包含了来自其邻结点的信息,那么如何让每个结点都感知图上所有结点的状态呢?答案就是重复进行上述过程,用迭代更新的方式来实现,用公式表示就是:
X(t+1) = F_w(x(t), l)
|| x(t) - x(t-1)|| <= \varepsilon_f
其中t+1表示t+1时刻, F_w 表示由若干个 f_w 堆叠得到的函数,是全局转移函数。那么对上方公式的理解是:不断的利用当前时刻的邻结点的状态和特征作为输入来生成下一时刻当前结点的状态,直到每个结点的状态趋于稳定。那么在t+1时刻结点n的状态如上方公式所示进行更新,直到结点n趋于某个稳定值,那么此时就可以认为结点n已经获取到了全局的信息,通过t时刻与t-1时刻的差的范数是否小于设定的阈值 \varepsilon 来判断是否趋于稳定值。将时刻带入传播与输出公式,可得:
x_n(t+1) = f_w(l_n, l_{co[n]}, x_{ne[n]}(t), l_{ne[n]})
o_n (t)= g_w(x_n(t),l_n)
Banach不动点理论是什么?
根据Banach的不动点理论,假设F 为压缩映射函数,那么下方公式有唯一不动点解,即可通过迭代更新的方式更新结点的状态,直到其逼近某个稳定值。
X(t+1) = F_w(x(t), l)
那么何为压缩映射呢?
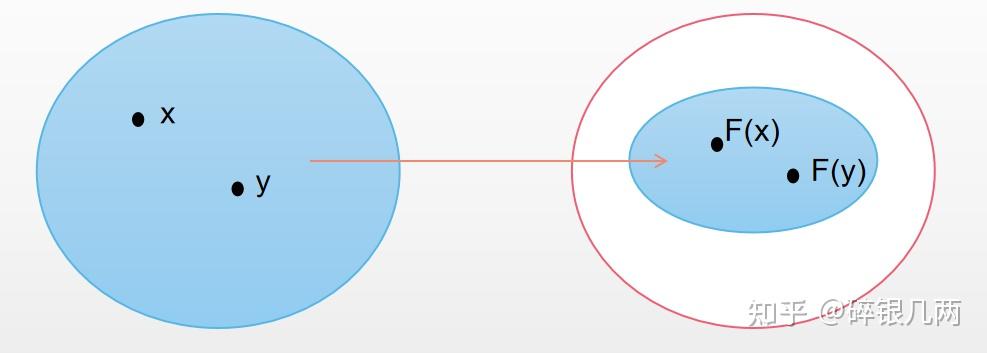
对于任意x,y,在经过映射F之后变成F(x)和F(y) , 如果 d( F(x), F(y)) <= k d(x,y) ,其中 0<= k <=1 ,此映射F为压缩映射(如下图)。理解:每进行一次映射,空间都会变得更小,那么在进行t次映射之后,空间将趋于某一个点,即原空间最终映射到一个点上。
, |
|



 发表于 2023-1-12 11:45:18
发表于 2023-1-12 11:45:18