|
|
我今天选用的数据集是:男性和女性身高和体重|卡格尔 (kaggle.com)
用神经网络进行一个简单的二分类。早知道Kaggle上有现成的数据集,在学逻辑回归的时候也就不用正态分布来生成数据了。(匀速小子:数学建模学习day23:逻辑回归模型)

这是在Kaggle的dataset里面,不是竞赛,所以test里面也是有Sex的,所以等下训练完可以直接测试。
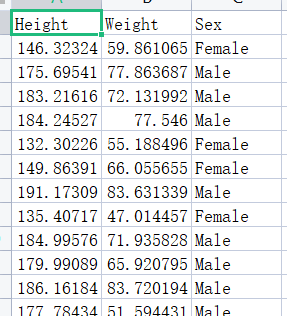
我们先来看看数据:
导入库函数:
#导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt打开训练集的文件:
train=pd.read_csv("Desktop\\male-female-height-and-weight\\Training set.csv")看看数据是否存在缺失值或者异常情况:(这步真的很重要,千万不要像搞形式主义那样敲了代码不检查数据)
display(train.describe())结果如下:
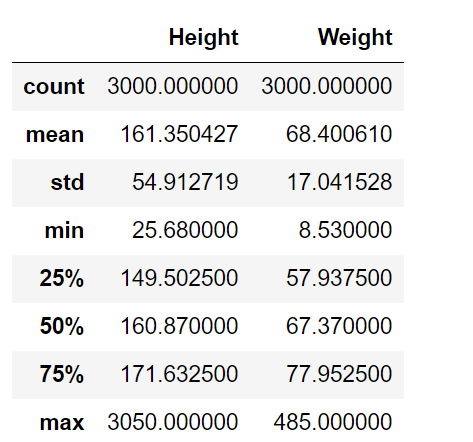
数据没有缺少,但是数据中可能是输入的时候错误,或者是数据中有巨人症和侏儒症的人,身高最高有30m,体重400多kg,这显然就是异常数据。这些数据会影响我们的预测,所以,直接丢弃。
这里规定,身高小于100cm或者大于220cm、体重小于20kg或者大于150kg的为异常数值。(就算有可能是小孩子也不管了)
先找出下标:
#异常值处理 身高小于100cm或者高于220cm的为异常值,体重小于20kg或者大于150kg的为异常值
error=[]#找出异常坐标,然后统一删掉
for i in range(len(train)):
height=train.loc[i:i].values[0][0]
weight=train.loc[i:i].values[0][1]
if height>220 or height<100 or weight<20 or weight>150:
error.append(i)3000条数据有5个:
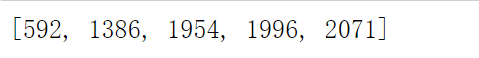
for i in error:
train=train.drop(i,axis=0)数据的“Sex”这里现在是字符串:
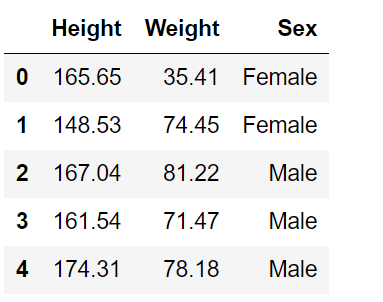
我这里将男性标号为1,女性标号为0。
train.loc[train[&#39;Sex&#39;]==&#39;Male&#39;,&#39;Sex&#39;]=1
train.loc[train[&#39;Sex&#39;]==&#39;Female&#39;,&#39;Sex&#39;]=0我们将数据分成train_X和train_y,然后将训练集释放掉:
train_y=train[&#39;Sex&#39;].values
train_X=train.drop([&#39;Sex&#39;],axis=1).values
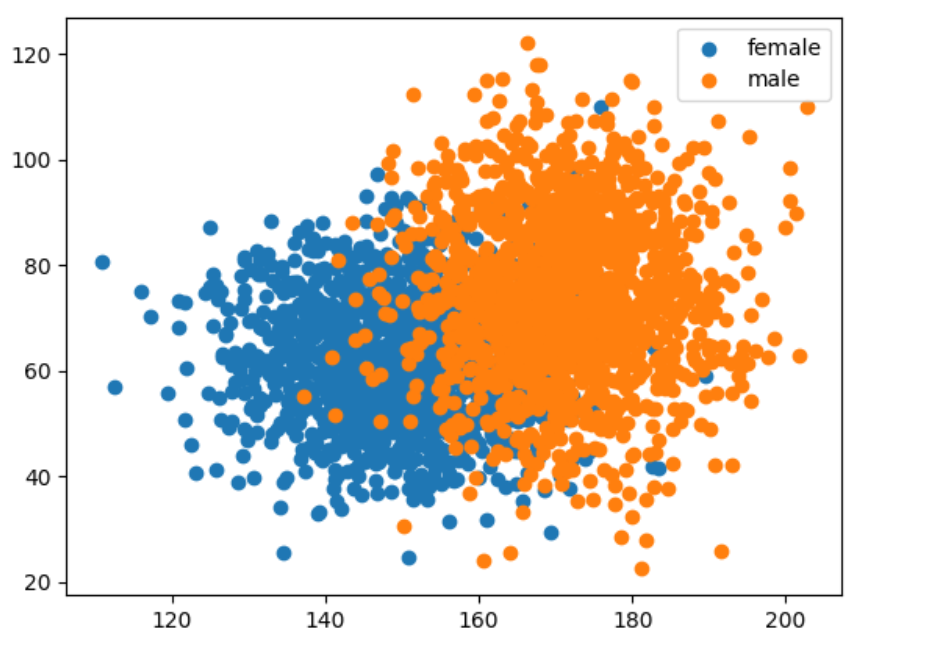
del train这里我们也可以作图,看看男性和女性在坐标轴上的分布是怎么样的。(代码见文末)
下面就是我构建的简单的神经网络,激活函数是Sigmoid函数。
我是按照这张图来构建神经网络的:
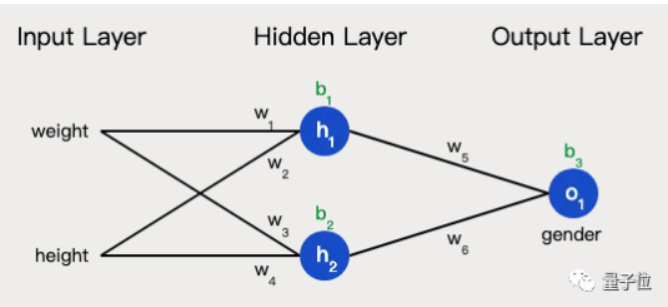
参考的文章:陈钢:用Python从头实现一个神经网络
类似的代码在网上也看到过几次,也不知道谁是原创。
比较好笑的是,我明明是码代码的能力差,结果在反向传播的导数求解验算了好多次,始终发现不了错误。就这样消耗了好长时间。
看了他的代码,好像是先要中心化处理,也就是将身高和体重的平均值移到坐标原点。
#中心化处理
sum1=0
sum2=0
for i in range(len(train_X)):
sum1+=train_X[0]
sum2+=train_X[1]
mean1=sum1/len(train_X)
mean2=sum2/len(train_X)
for i in range(len(train_X)):
train_X[0]-=mean1
train_X[1]-=mean2我的代码:(自用,读者建议网上查找代码或者看他的代码)
def PRelu(x):
return x if(x>0) else x/2
def PRelu_x(x):
return 1 if x>0 else 1/2
def sigmoid(x):
return 1/(1+np.exp(-x))
def sigmoid_x(x):
return sigmoid(x)*(1-sigmoid(x))
#激活函数
def active(x):
#return PRelu(x)
return sigmoid(x)
def active_x(x):
#return PRelu_x(x)
return sigmoid_x(x)
def loss(y_hat,y):
los=0;n=len(y)
for i in range(n):
los+=(y-y_hat)**2
return los/n
def loss_y(y_hat,y):
return -2*(y-y_hat)
def fit(train_X,train_y):
alpha=0.001#学习率
w=[0.1,0.1,0.1,0.1,0.1,0.1];b=[0.1,0.1,0.1]#随便设置初始值
for i in range(100):#迭代100次
predict_y=predict(train_X,w,b)
los=loss(predict_y,train_y)#损失函数
G=get_G(train_X,train_y,predict_y,w,b)#获取梯度
dw=G[:6]
db=G[6:]
w-=alpha*dw
b-=alpha*db
return w,b
#获取梯度
def get_G(train_X,train_y,predict_y,w,b):
G=np.array([0 for i in range(len(w)+len(b))])
w1,w2,w3,w4,w5,w6=w
b1,b2,b3=b
for i in range(len(train_X)):
ans=[]
height=train_X[0]
weight=train_X[1]
#第一层
h1=height*w1+weight*w2+b1
h2=height*w3+weight*w4+b2
#激活
h1_active=active(h1)
h2_active=active(h2)
#第二层
o1=h1_active*w5+h2_active*w6+b3
#激活
p=active(o1)
los=loss_y(p,train_y)#损失函数对概率求导
ac=active_x(o1)#概率对o1求导
res=los*ac#这是公共的求导部分
#分别对9个参数求导
ans.append(res*w5*active_x(h1) *height )#w1
#self.w1 -= learn_rate * -2 * (y_true - y_pred) * self.w5 * deriv_sigmoid(sum_o1) * x[0] * deriv_sigmoid(sum_h1)
ans.append(res*w5*active_x(h1) *weight )#w2
ans.append(res*w6*active_x(h2) *height )#w3
ans.append(res*w6*active_x(h2) *weight )#w4
ans.append(res*h1_active )#w5
ans.append(res*h2_active )#w6
ans.append(res*w5*active_x(h1) )#b1
ans.append(res*w6*active_x(h2) )#b2
ans.append(res )#b3
ans=np.array(ans)
G=G+ans
return G
def predict(test_X,w,b):
predict_y=[]
for i in range(len(test_X)):
height=test_X[0]
weight=test_X[1]
w1,w2,w3,w4,w5,w6=w
b1,b2,b3=b
#第一层
h1=height*w1+weight*w2+b1
h2=height*w3+weight*w4+b2
h1_active=active(h1)
h2_active=active(h2)
o1=h1_active*w5+h2_active*w6+b3
p=active(o1)
predict_y.append(p)
return predict_y这样就能求解出参数w和b:
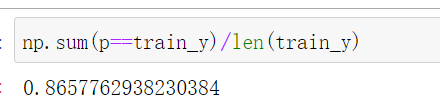
w,b=fit(train_X,train_y)预测,注意,我这里的代码求解出来的是概率,所以还必须得判断是男性(1),还是女性(0).
p=predict(train_X,w,b)
p=np.where(np.array(p)<0.5,0,1)预测的准确率也就86%。
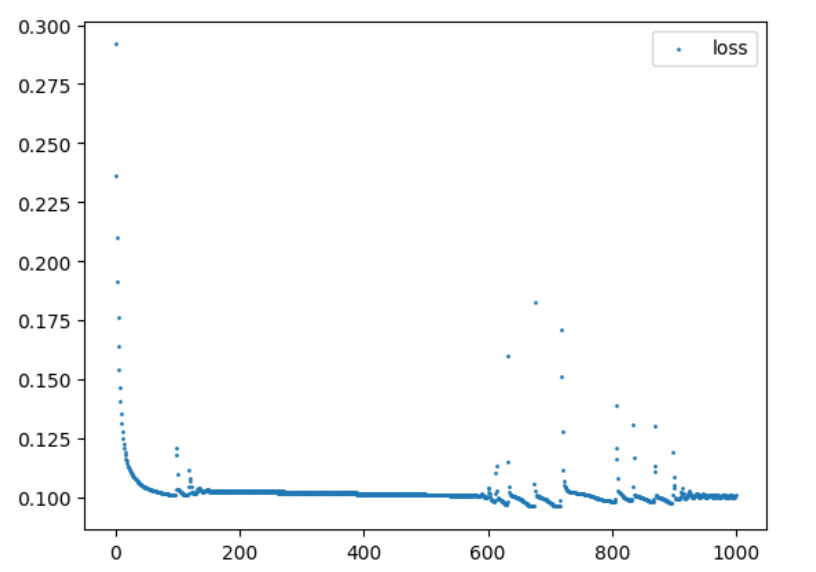
绘制的损失函数的图像:
下面是一些Python代码:
Python散点图代码:
female_height=[]
female_weight=[]
male_height=[]
male_weight=[]
for i in range(len(train_X)):
if train_y:#男性标号为1
male_height.append(train_X[0])
male_weight.append(train_X[1])
else:
female_height.append(train_X[0])
female_weight.append(train_X[1])
plt.scatter(female_height,female_weight,label=&#34;female&#34;)
plt.scatter(male_height,male_weight,label=&#34;male&#34;)
plt.legend()
plt.show()PRelu函数:
def PRelu(x):
return x if(x>0) else x/2
x=[i/100-5 for i in range(1000)]
y=[PRelu(x) for i in range(1000)]
#调整大小
plt.figure(figsize=(6,6))
#获取当前坐标轴
ax = plt.gca()#get current axes
#右边和上面的坐标轴透明
ax.spines[&#39;top&#39;].set_visible(False)
ax.spines[&#39;right&#39;].set_visible(False)
#调整坐标轴位置
ax.spines[&#39;bottom&#39;].set_position((&#39;data&#39;, 0))
ax.spines[&#39;left&#39;].set_position((&#39;data&#39;, 0))
plt.scatter(x,y,s=1) |
|



 发表于 2023-1-17 17:54:16
发表于 2023-1-17 17:54:16